BioHPC Next Generation Sequencing Support
We are currently extending BioHPC to suport the analysis of
next generation sequencing results. BioHPC now features web and web service interfaces
to the following analysis applications:
FASTX, SamTools, Bowtie, TopHat, Cufflinks, BWA, and RNASeq -
a new RNA-Seq analysis pipeline developed at Cornell. All these applications interact with
a new Next-Gen data managament module designed for storage and management of various
(usually large) data files involved in the analysis. The module automatically captures
the Illumina sequencing results as well as files produced by analysis
applications and makes them available for further processing at BioHPC site without
the need for back-and-forth file transfer between our servers and the users' client machines.
More specifically, the data management module consists of several components:
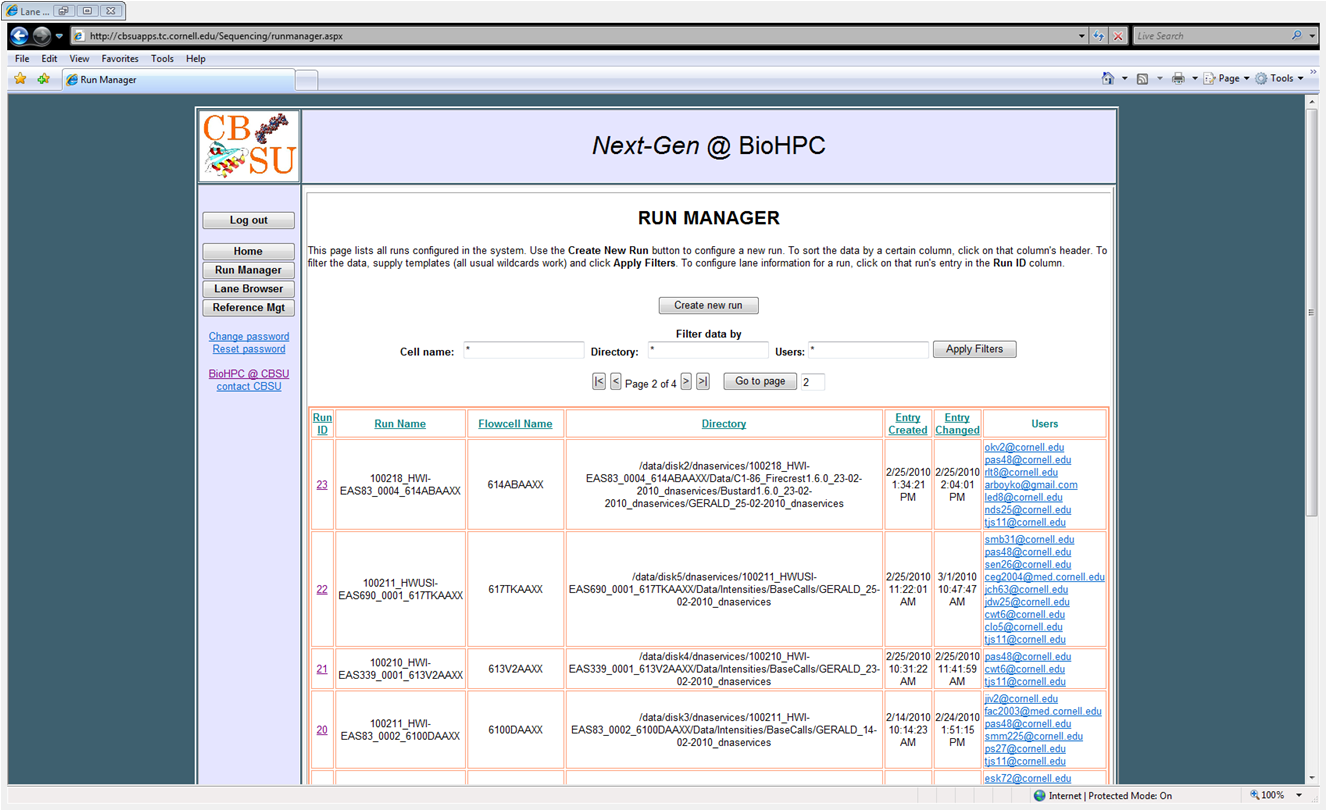
Run Manager: connects to the sequencing facility and automatically detects finished sequencing runs for which base calling has been completed. It then configures the run in BioHPC database and sends an invitation to the facility manager to approve the results for distribution to users. Once approved, the results (read files) are asynchronously transferred to BioHPC file server and catalogued there for further use. Once the transfer is complete, all users assigned to distributed lanes are automatically notified by an e-mail message containing download links.
Lane Browser: allows users to browse their sequencing read files (Illumina lanes) catalogued at BioHPC. The browser displays lane annotation information and allows the file owner to grant additional users access to a file. Read files obtained outside of the Cornell sequencing facility can also be uploaded and catalogued at BioHPC.
File Manager: allows users to upload and manage various files needed in downstream data analysis, such as reference genome files and annotation files. Files may be assigned categories and descriptions, and shared between several users.
Besides the data management module,
BioHPC features a Pipeline Manager (currently in beta-version) which
allows users to streamline their calculations by connecting multiple Next-Gen applications into
analysis pipelines. Each pipeline step is individually configurable using
web interface page of the corresponding application, with input files selected either from
among the files registered in the data management module or from files anticipated from
previous pipeline steps. The pipeline steps are submitted to our clusters as regular BioHPC jobs
so that standard BioHPC mechanisms can be used for job control and result retrieval.
Users set up and control pipelines using our
specially constructed web interface, although we are also planning a web service layer serving
this purpose. The web service interface will allow pipelines
to be controlled from any client application, such as the MBF platform,
Illumina Genome Studio, or Trident scientific workflow workbench.
The new module is currently geared to handle mainly Illumina sequencing results, but extensions are possible.
Below are screenshots showing some aspects of
next generation sequencing support module.
|
Run Manager: Intercept finished sequencing runs and
configure them in BioHPC data manager for sequencing
administrator to review and approve for distribution:
|
Run Manager: Notify sequencing facility administrators
about the new results to be approved for distribution to users.

|
|
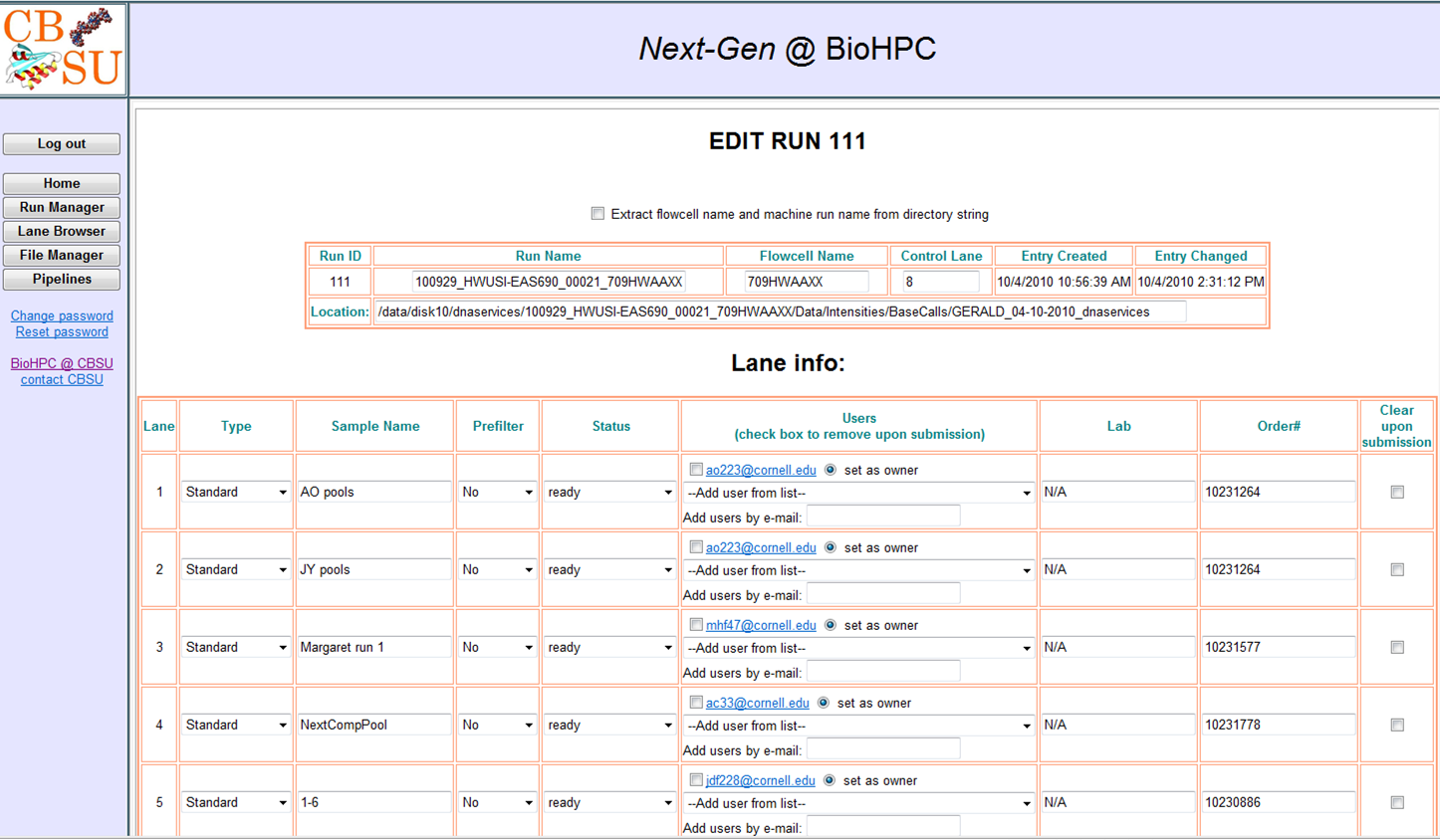
Run Manager: Approval page for sequencing facility.
Transfer (asynchronous) to BioHPC will start after a lane status
is changed to approved.
|
Lane Browser: Main administration page for lanes. Users can only
manage their own data.
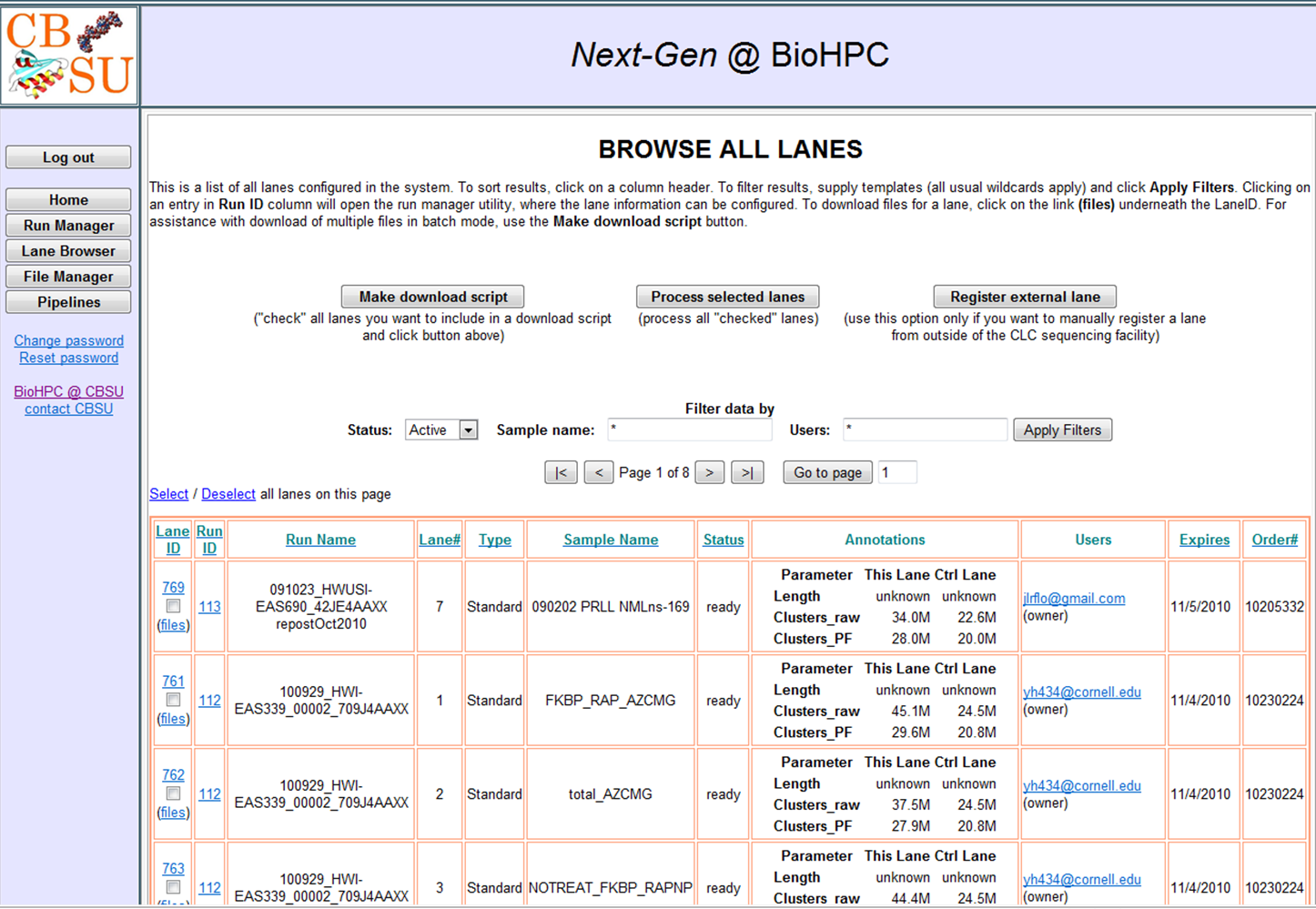
|
|
Run Manager: Once data files are transferred users obtain links
to download them.
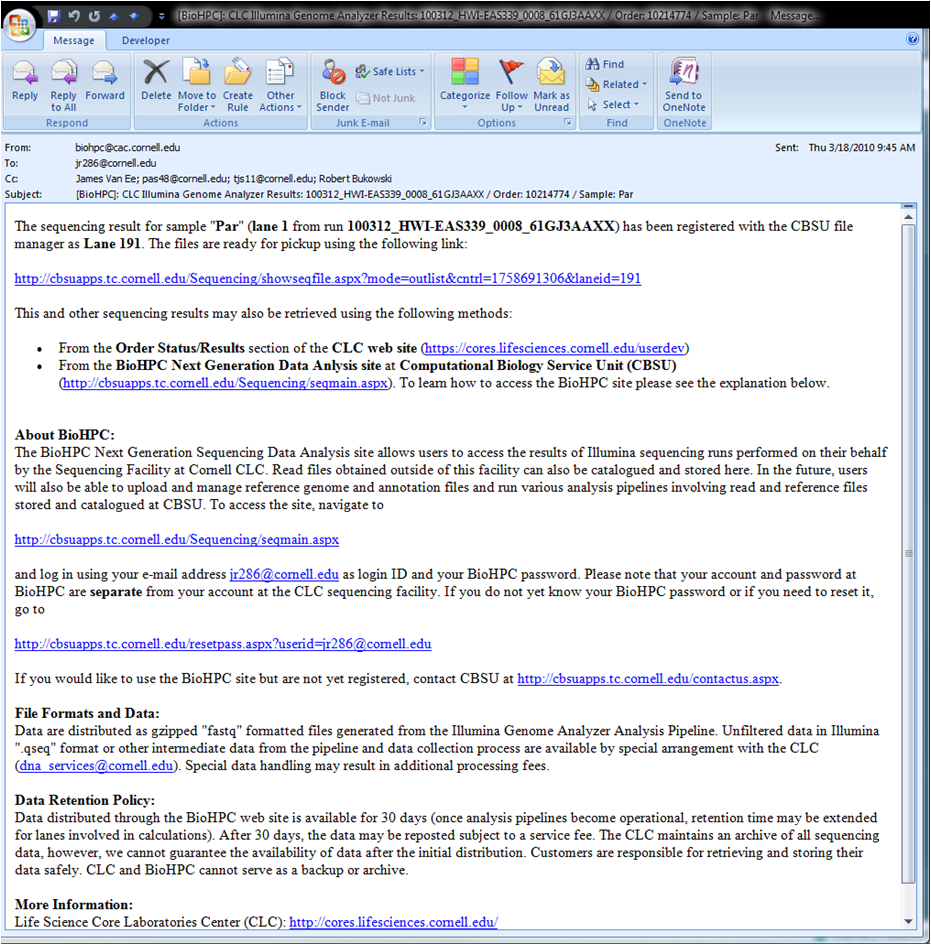
|
Lane Browser: User data download page.
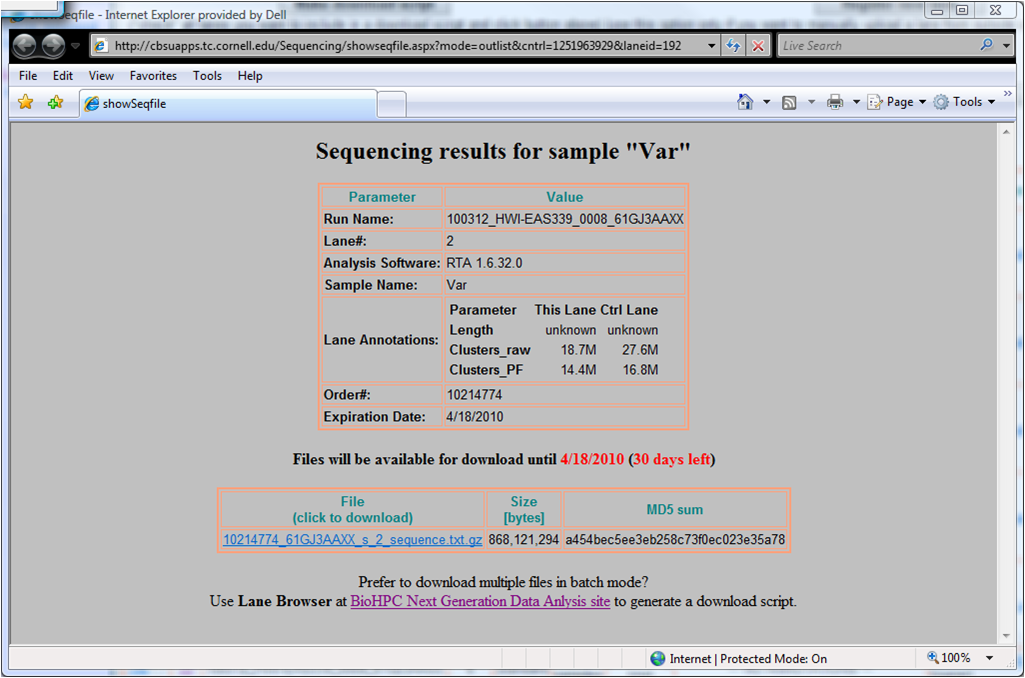
|
|
File Manager:
Users can only see files they have access to.

|
An application submission page: input files are
selected from among the ones registered in data management module
or from among the output files of previous pipeline steps (if
the run is a pipeline step).
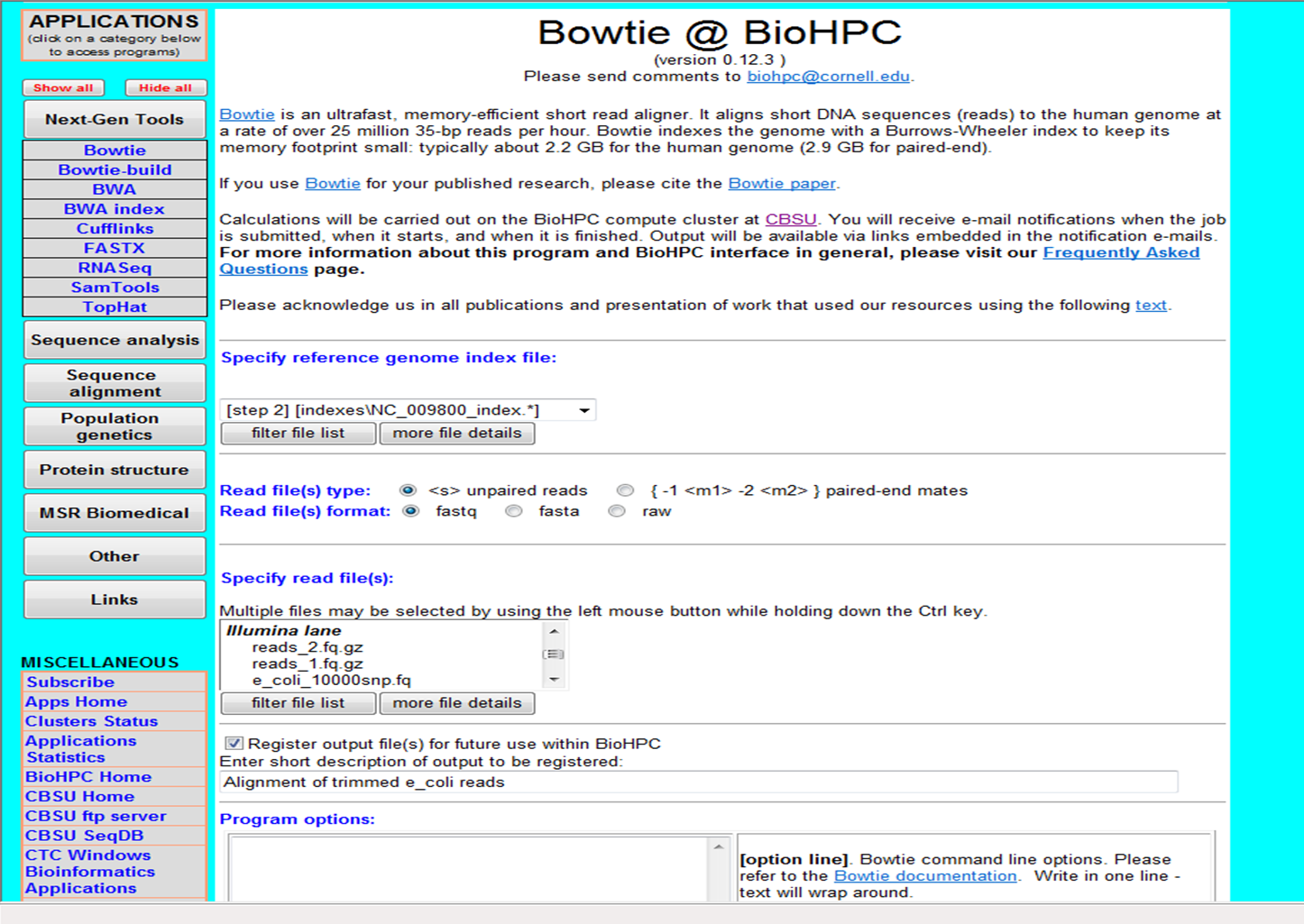
|
|
Pipeline Manager: Running pipeline. Steps are connected through the
output files whose names are color-coded for clarity.
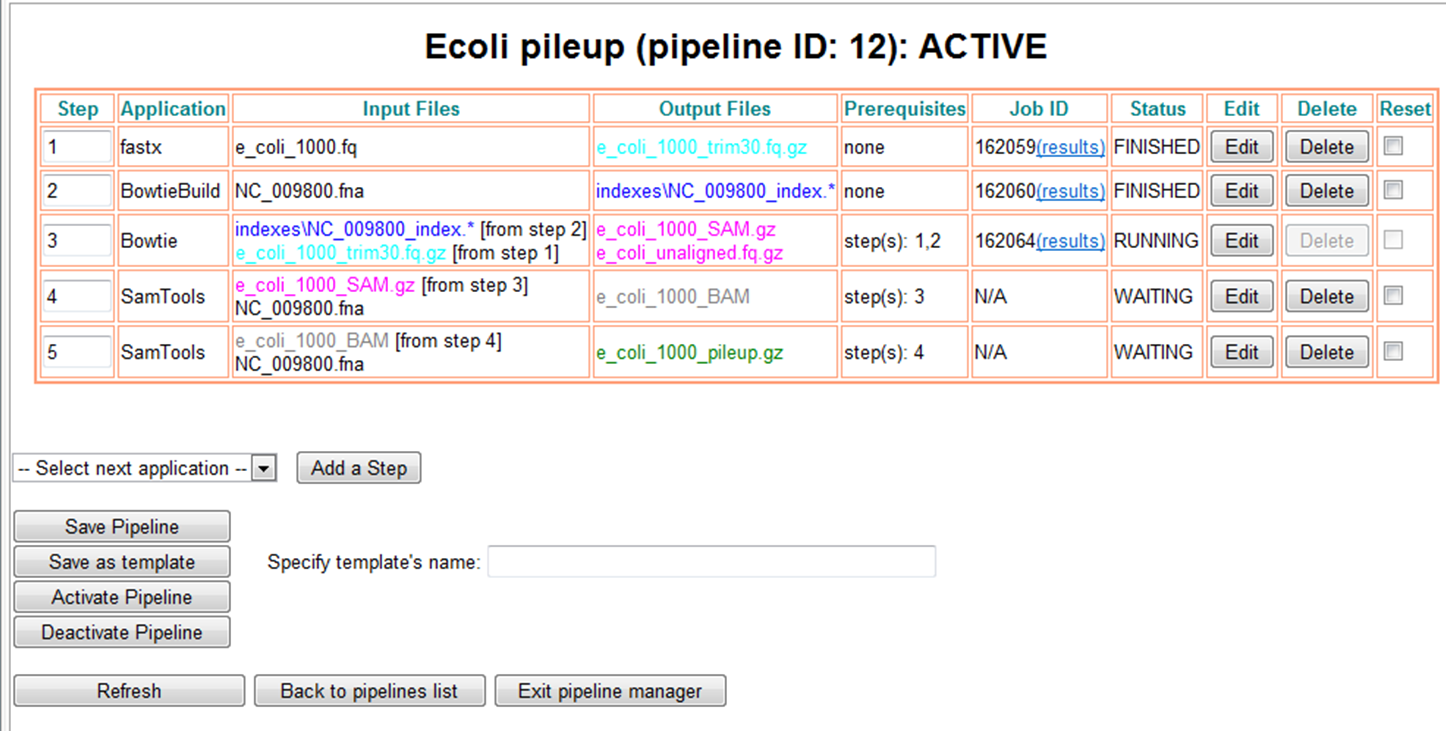
|
Pipeline Manager: Finished pipeline. Results are retrieved
using standard BioHPC mechanisms.
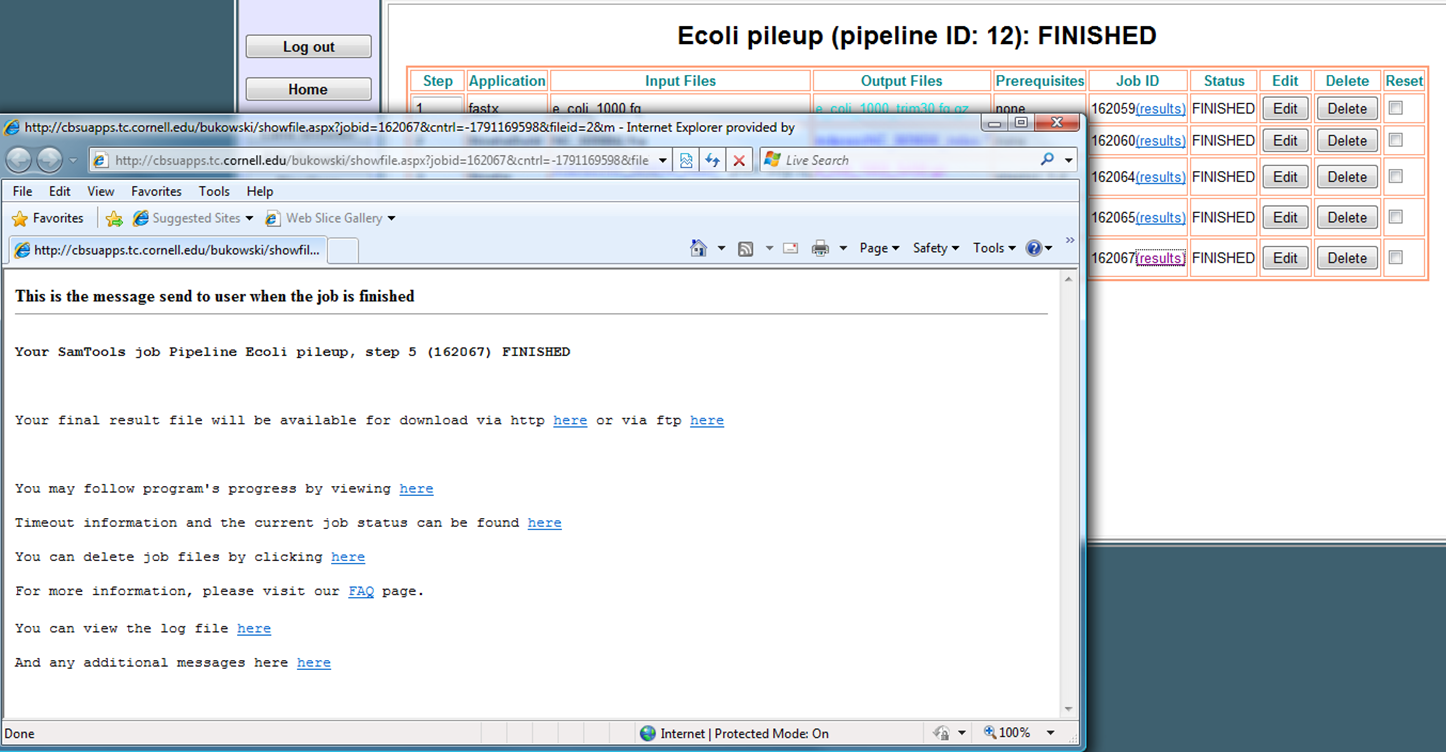
|