BioHPC: Architecture
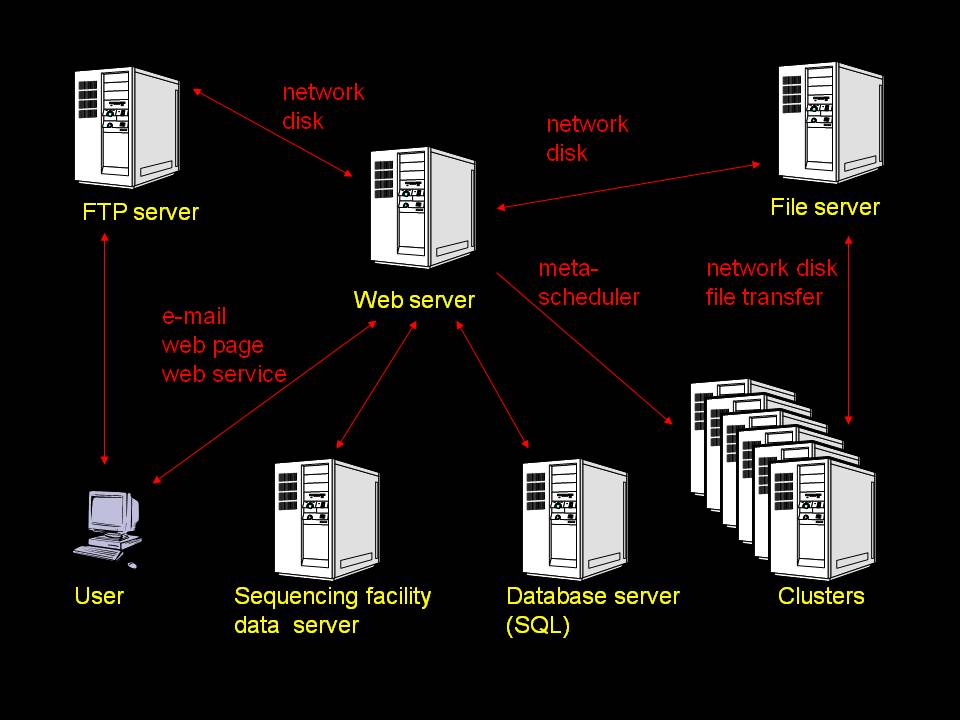 The
system consists of a web server running the interface (ASP.NET C#),
Microsoft SQL server (ADO.NET), compute clusters running Microsoft
Windows, ftp server and file server. Two local compute cluster
schedulers are supported (CCS and HPC Server 2008), remote clusters
can be used via JSDL/HPC Basic Profile. Users interact with their jobs and data
primarily by a web browser and e-mail. Jobs are submitted through
our active web pages, fully compatible with all the popular web
browsers supporting DOM and Javascipt. Notification e-mails sent to
users upon job submission, start, and completion contain links for
job progress monitoring, job cancellation and restart, and results
retrieval (by http or ftp). Job and data control functions can also
be performed via a recently developed web service interface which
enables users to build custom clients independent of the web
browser. The number of applications offered through the web service
(currently 10) is growing.
The
system consists of a web server running the interface (ASP.NET C#),
Microsoft SQL server (ADO.NET), compute clusters running Microsoft
Windows, ftp server and file server. Two local compute cluster
schedulers are supported (CCS and HPC Server 2008), remote clusters
can be used via JSDL/HPC Basic Profile. Users interact with their jobs and data
primarily by a web browser and e-mail. Jobs are submitted through
our active web pages, fully compatible with all the popular web
browsers supporting DOM and Javascipt. Notification e-mails sent to
users upon job submission, start, and completion contain links for
job progress monitoring, job cancellation and restart, and results
retrieval (by http or ftp). Job and data control functions can also
be performed via a recently developed web service interface which
enables users to build custom clients independent of the web
browser. The number of applications offered through the web service
(currently 10) is growing.
Users can interact with their jobs and data by a web browser, ftp or
e-mail. The jobs are currently submitted through BioHPC active server
web pages, users are provided with links for job progress monitoring.
When a job is finished an e-mail with link to final results (by http or
ftp) is sent. The jobs can be cancelled, stopped and restarted by users
through a set of urls provided at the time of submission. The interface
has also a built in user management system which can limit software
and/or database access to specified users. Data access between different
users is restricted – users can access only their own jobs and data,
even when working as guests. There is also administrative interface
allowing for easy management of jobs, users, applications with automatic
e-mail notification of possible problems.
Compute clusters
Two MS Windows based systems are supported:
- MS Windows HPC Server 2008 is supported on all x64
hardware platforms. MS MPI is used for parallel communication.
- MS Windows Compute Cluster Server 2003 is
supported on all x64
hardware platforms. This is an older version of Microsoft HPC platform. MS MPI is used for parallel communication.
Web server
- Web server is required, but it does not need to be a separate
machine. It can be installed on head node.
- The interface is written in C# on ASP.NET
platform.
- Web pages use Javascript on the client browser
and ASP on the server side.
- It is fully compatible with all popular web
browsers supporting DOM and Javascipt.
- CBSU web server is running MS Windows Server
2003, but MS Windows Server 2008 is also supported.
- Windows SDK and .NET 3.5 are required.
File server
- File server is required, but it does not need to be a separate
machine. It can be installed on cluster head node or on web server.
- Network drive is used for simple data exchange and sharing between
nodes
- Network drive is also available from outside
the cluster for web server
- It is essential for computational biology
applications to maintain local HD storage (~50GB) on nodes for sequence
databases
- Current BioHPC@CBSU file server has capacity of
6TB of storage
Ftp server
- FTP server is optional, and may be located on head node or web
server or file server
- FTP server is used for long term storage of finished job’s results
- It is also used for transferring input/output
data files that are too big for http transfer
- BioHPC@CBSU FTP server runs MS Windows Server 2003
and has storage capacity of 6TB
SQL server
- SQL server is required, but it does not need to
be a separate machine. It may be installed on head node, web server or
other machine.
- Full MS SQL server is NOT necessary, MS SQL Server Express Advanced
(free) may be used.
- SQL server is used to store and manage user and interface
information.
- It generates unique job id during submission,
and keeps all further job information
- MS Windows Server 2003 and MS SQL Server 2005.