BioHPC Home
BioHPC
Computational Biology Application Suite for High Performance Computing
Using BioHPC
Users can interact with their jobs and data by a web browser, ftp or
e-mail. The jobs are currently submitted through active web pages, users
are provided with links for job progress monitoring. When job is
finished an e-mail with link to final results (by http or ftp) is sent.
The jobs can be cancelled, stopped and restarted by users through a set
of urls provided at the time of submission.
 Each
application can be accessed via a standardized web page providing
controls and options. User can upload, paste or copy their input (or
data) files, select application specific options available on the page,
or specify additional options as a command line parameter.
Each
application can be accessed via a standardized web page providing
controls and options. User can upload, paste or copy their input (or
data) files, select application specific options available on the page,
or specify additional options as a command line parameter.
Each web page is standardized as much as practical. Administrator can
regulate access to applications: some of them may be restricted to all
(or some) registered users, some may be open to everyone.
Users can upload their data files (queries or databases) via http, place
them on local ftp server, or use their local network drive. Registered
users can register their uploaded databases so they are kept permanently
and they don't need to upload them again.
In addition to application-specific options, users can choose number of
nodes, scheduler, and cluster. There is a page (nodes,aspx) providing
information about the current status of the clusters, waiting times (if
any) and free nodes. This page does not disclose any information about
the users.
For trivially parallelized programs extensive control over task
performance is provided, preventing waste of computational resources in
a case of errors in input. This is especially important for BLAST, where
inappropriate input may hang the program, blocking some of the nodes.
There is a timeout setting allowing the interface to detect possible
problems, and these setting can be updated dynamically during the run.
Some application-specific options are available on the interface, some
rarely used ones can be entered as a command line string .
 After
a job is submitted an email is dispatched with links to output files
and job control functions. These links are also available on the web
page displayed after job submission along with submit process
information (useful when something goes wrong). Another e-mail is sent
when the job starts, and another
when it ends. Jobs interact with users
via such e-mails. Links in the e-mail allow for viewing current results,
computations progress (log) as well as cancelling the job if necessary.
Sometimes a job finishes prematurely. Usually it happens for a very long
jobs run on relatively small number of nodes. Many applications can be
restarted and continued from the stopping point via a link embedded in
the premature notification e-mail.
After
a job is submitted an email is dispatched with links to output files
and job control functions. These links are also available on the web
page displayed after job submission along with submit process
information (useful when something goes wrong). Another e-mail is sent
when the job starts, and another
when it ends. Jobs interact with users
via such e-mails. Links in the e-mail allow for viewing current results,
computations progress (log) as well as cancelling the job if necessary.
Sometimes a job finishes prematurely. Usually it happens for a very long
jobs run on relatively small number of nodes. Many applications can be
restarted and continued from the stopping point via a link embedded in
the premature notification e-mail.
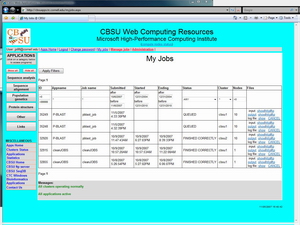 Registered
users have access to their job history, where they can control the jobs
via same links as in the notification e-mails and retrieve results. The
time period for which the jobs are kept on the BioHPC servers is
controller by the administrators.
Registered
users have access to their job history, where they can control the jobs
via same links as in the notification e-mails and retrieve results. The
time period for which the jobs are kept on the BioHPC servers is
controller by the administrators.